Vulkan x CUDA x TensorRT x LibTorch
By YXHXianYu
tl;dr
图形API与CUDA都是用于操作显卡的工具,通过其中一系列平台相关的API,我们可以让这些工具同时访问同一块显存,从而实现Texture、Buffer、同步原语的共享,因此,我们就可以在硬件渲染器中接入CUDA算子。
关于网络模型,我们可以将其导出为ONNX格式,然后在C++中通过TensorRT库导入并运行网络。
项目代码已开源在Github:(link)。这个功能被整合在了我们组的渲染引擎MoerEngine中,关于代码实现的具体问题可以查阅文档:DeepWiki
1. 背景
咸鱼鱼(笔者)目前负责组里实时渲染器MoerEngine的维护。某天,组内的横向项目出现了一个需求,需要将一套诞生自PyTorch的网络接入一个实际渲染器,进行集成测试,从而验证网络效果。
渲染器的备选有Unreal Engine、Unity、和我们组的MoerEngine。总之,出于多种原因(造轮子的快感),最后我们选择在组里的渲染器中尝试接入网络。
在开发过程中,我遇到了许多的工程细节问题。其中大部分问题,互联网上都没有类似问题的记录,AI也无法给出正确的解答,并且许多问题没有任何错误信息,只能自己瞎猜和尝试。因此,这需要花费大量的时间。所以,我在解决这些问题的过程中,便将自己遇到的问题整理出来,以节约后续其他开发者的时间。
这些问题的内容涵盖了项目的方方面面、并十分零散。因此,本文主要会以 Q&A 的形式呈现。
需要注意的是,本文并不是一个Vulkan与CUDA互操作的教学,而是一个列出了互操作中可能出现的疑难杂症与对应解决方案的列表。如果你想实现类似的功能,推荐参考相关的教学文章、官方样例代码、或者 MoerEngine代码。
如果这篇文章对你有帮助,欢迎给MoerEngine的仓库点一个star。
2. 思路
2.1 Why?
首先,Vulkan和DirectX等图形API 与 CUDA 都是用于操作显卡的API。有同时学习过这两类API的同学就会发现,这两类API的许多操作都十分相似,只不过侧重点不同。
图形API专注于图形渲染任务,提供了一套用于绘制图形和处理图形数据的接口;而CUDA则主要用于通用计算任务,允许开发者编写并行计算代码,以充分利用GPU的计算能力。但随着图形API的发展,目前的现代图形API也都支持计算着色器和计算管线,这使得图形API在多种场景上也具备了类似CUDA的并行计算能力,并且还有间接绘制等数据驱动的功能。相比之下,CUDA的优势则是更易于上手,并且拥有更成熟的生态(如cuBLAS、TensorRT等库),这使得开发者能够更方便地实现复杂的并行计算任务和深度学习推理任务。
因此,在实际场景中,混合使用图形API和CUDA是一个合乎逻辑的思路:让图形API来实现基本渲染管线,让CUDA来实现各种网络和数据处理。
2.2 原理:Vulkan CUDA 互操作
Vulkan和CUDA都是用于操作显卡的API。通常来说,Vulkan会从Texture/Buffer中读取数据,并写入到其他Texture/Buffer中,并通过信号量来在不同Pass之间进行同步。CUDA也同样,会在Buffer上进行读写。这些Texture和Buffer都是位于显存上的。
所以,如果有一个API,可以直接让Vulkan和CUDA共享这些Texture、Buffer、信号量,那么我们就可以实现这两类工具的互操作,从而在一个渲染器中同时使用Vulkan和CUDA。
Vulkan从1.1版本开始便默认启用相关的拓展,具体可以参考 官方文档 External Memory and Synchronization。
CUDA从某个版本开始,也支持了外部资源互操作能力,具体可以参考 官方文档、官方样例代码。
Ok,现在,我们知道了这件事可以做,接下来只需要按照示例代码和文档一步一步走就行了!
2.3 原理:PyTorch网络在C++中运行
PyTorch是一个Python深度学习框架。ONNX (Open Neural Network Exchange) 是一个用于表示网络的中间格式,就类似三维模型中的glTF和fbx。TensorRT是NVIDIA的一个ONNX推理引擎,支持解析ONNX,将其编译到特定平台上并进行推理。
所以,我们可以在PyTorch中,把模型和参数都导出为ONNX格式。然后,在C++项目中,引入CUDA、LibTorch、TensorRT这三个依赖库,并对ONNX进行解析和推理。
需要注意的是,LibTorch和TensorRT都基于特定CUDA版本运行。换句话说,TensorRT的底层依赖于CUDA。
2.4 总体流程
首先,假设我们已经有了一个正常运行的Vulkan渲染器。
考虑CUDA:
- 引入CUDA依赖库
- 编写CUDA代码,在CMake等构建系统中编译CUDA代码,并将其链接到主模块中
- 通过Vulkan中 操作系统相关的API,将Vulkan申请的显存进行导出,使用CUDA API设置这些显存的解析方式(纹理布局等),并将其导入CUDA
- 将同步原语绑定到对应的对象上,确保RenderPass和CUDA kernel会按理想顺序执行
- 执行CUDA kernel
考虑神经网络(假设PyTorch导出的ONNX格式网络不包含任何插件):
- 引入LibTorch和TensorRT
- 使用TensorRT解析ONNX
- 将CUDA Buffer和网络输入输出Tensor绑定在一起
- 绑定同步原语
- 执行网络推理
理想的话,我们就只需要这些基础的步骤便可以完成这些操作。接下来,就是非常 地狱 的各类技术细节。
3. 技术细节 Q&A
本小节的内容比较杂乱无章。所以如果你是带着问题来的,那么推荐直接使用搜索功能。(或者将本文塞给AI)
此外,一些问题只有截图记录。所以如果你在找特定问题,也请仔细查阅一下本章的图片。
3.1 编译CUDA (CMake)
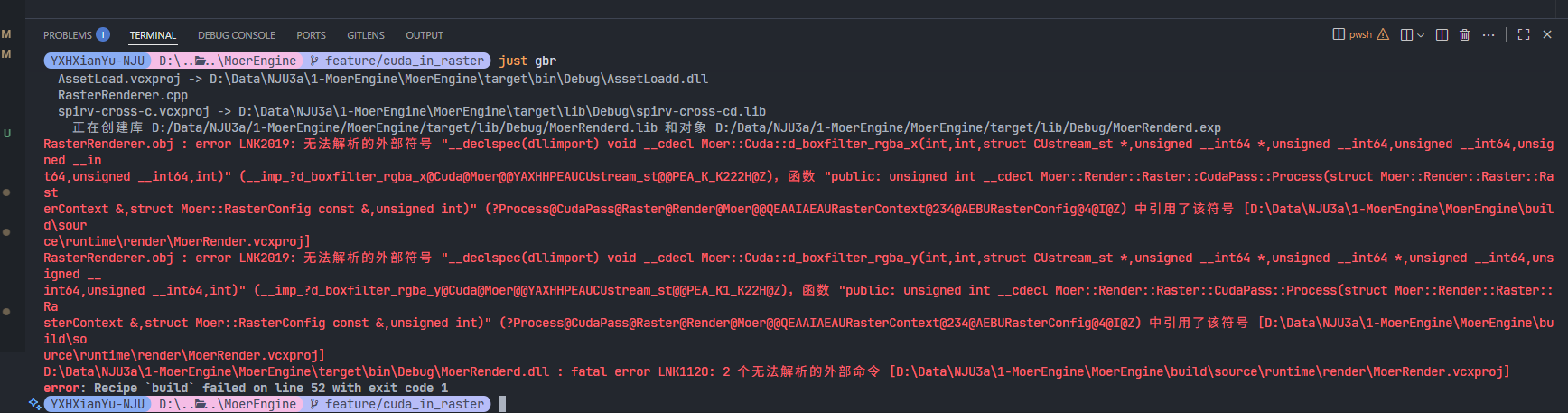
问题:链接不上怎么办?有没有什么排查思路?(无法解析的外部符号)
检查是否有函数实现
检查
.cpp/.cu文件是否include了对应的.h文件检查函数签名是否一致(namespace)
检查是否位于同一模块;若为否,检查是否添加了
__declspec(dllexport)检查对应文件是否被构建(在
build目录下搜索是否出现了xxxx.cpp)检查对应
.dll文件是否有函数签名,即执行dumpbin /exports ".\path\to\MoerEngine\target\bin\Debug\moer_cudad.dll" > ~/Desktop/log.txt
问题:见下图
-

- 原因1
- moer_cuda这个模块没有被编译,这个模块直接被跳过了,所以找不到对应库文件
- 解决方案1
- 在顶层CMakeLists.txt的
project()中添加CUDA
- 在顶层CMakeLists.txt的
- 原因2
- 没有在CUDA模块中添加
dllexport标记 - msvc会认为这个模块导出内容为空,所以忽略这个模块
- 没有在CUDA模块中添加
- 解决方案2
- 在CUDA模块中,函数声明处,添加
__declspec(dllexport) - 注:此处最佳实践是添加一个导出宏,具体可以参见MoerEngine/source/cuda中的
MOER_CUDA_API
- 在CUDA模块中,函数声明处,添加
-
问题:编译时,提示
nvcc fatal: A single input file is required for a non-link phase when an outputfile is specified原因
- CMake、msvc和nvcc的兼容性比较烂,导致nvcc编译指令出错。
解决方案
if(${MSVC})
set_target_properties(moer_cuda PROPERTIES COMPILE_OPTIONS -Xcompiler)
endif()
问题:是否要将LibTorch、TensorRT直接以第三方库的形式引入引擎源码?
思路
总所周知,对于大多数C++库,将其以源码的形式引入自己的项目,是一个高效的方法,不需要用户自己使用包管理器、或者手动下载各类依赖库。同时,LibTorch和TensorRT都依赖于特定的CUDA版本(例如必须要CUDA12.8)
那么,我们就有两个方案:
要求用户安装CUDA12.8
CUDA、LibTorch、TensorRT全部让用户自己安装,并且自己进行配置
最后,我们选择了方法2。因为深度学习拓展对MoerEngine并不是必须的,没必要为了一个拓展,从而让整个引擎变得过于重型
解决方案
- 在根目录下新建一个
template.EnableCuda.cmake的模板文件,并且让git追踪该文件 - 如果用户需要启用CUDA相关特性,则可以根据该模板生成一个
EnableCuda.cmake;构建系统会自动检测是否存在这个文件,并读取其中的LibTorch和TensorRT目录,进行配置
- 在根目录下新建一个
问题:编译通过,但是启动后exe直接崩溃
原因
- 没有把LibTorch和TensorRT的lib目录添加到PATH中
- 导致运行时找不到动态库文件
.dll
解决方案
- 添加一下
3.2 Vulkan x CUDA
接下来的问题,主要是在渲染器中调用CUDA kernel时所遇到的问题。
为了化简问题,在实现的时候,只考虑Windows11 + Vulkan(即 绕开RHI,来实现本功能)。在代码实现时,我们引入了宏
WITH_CUDA=1,通过这个宏来在特定情况下添加代码。
- 问题:导出内存,需要先获取Vulkan申请的内存
VkDeviceMemory。但是为什么我在MoerEngine里找不到申请到的内存VkDeviceMemory?- 因为MoerEngine使用了 VMA (Vulkan Memory Allocator)
- VMA是一个Vulkan官方的内存分配器
- 注意,MoerEngine使用的VMA版本是官方仓库2025.10.5时main分支的代码
- 我们需要使用VMA的API,才可以获取
VkDeviceMemory
- 因为MoerEngine使用了 VMA (Vulkan Memory Allocator)
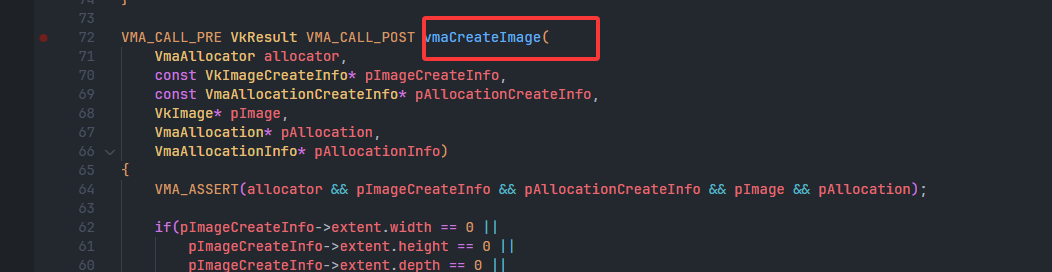
- 问题:VMA中没搜到提供
VkDeviceMemory的API,怎么办?- 翻了一下vma的源码
-
-
-
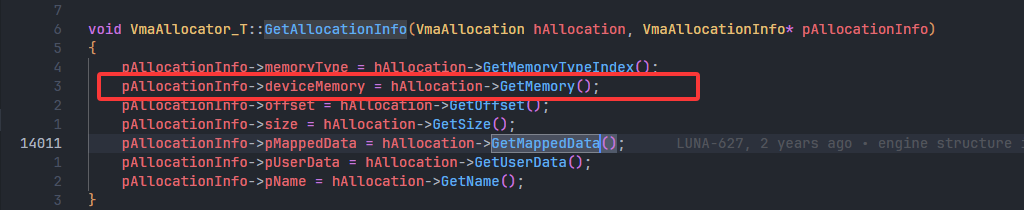
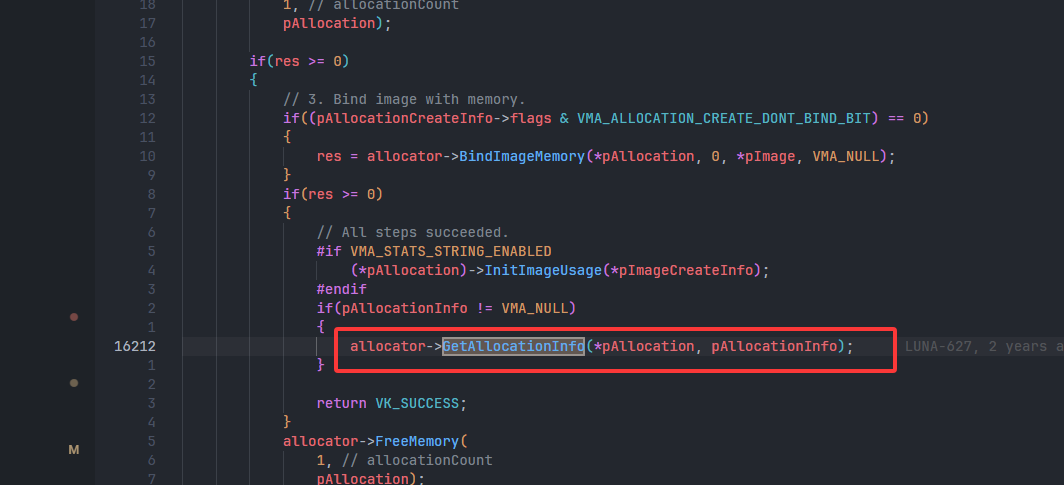
- 可以发现,关键类型就是
VmaAllocationInfo,这个类型专门用于提取信息
-
- 根据这个类型,可以找到这个接口
vmaGetAllocationInfo,这才是我们需要的
- 翻了一下vma的源码
3.2.1 大坑:获取内存Handle时崩溃
问题:在
vkGetMemoryWin32HandleKHR()崩溃- 原因 & 解决方案
- 没有启用Vulkan拓展,导致找不到这个函数,需要启用一下对应Vulkan拓展
- 原因 & 解决方案
问题:运行时,在
vkGetMemoryWin32HandleKHR()崩溃详细错误信息
vkGetMemoryWin32HandleKHR(): pGetWin32HandleInfo->memory pNext chain does not contain an instance of VkExportMemoryAllocateInfo.
The Vulkan spec states: handleType must have been included in VkExportMemoryAllocateInfo::handleTypes when memory was created原因
tl;dr:导出显存时,要求对应显存在创建的时候,就已经打上win32导出标记。否则就会崩溃
根据错误信息,我们要在创建这个内存的时候,就传入特定的
handleType- 即 VK_EXTERNAL_MEMORY_HANDLE_TYPE_OPAQUE_WIN32_BIT
- 但是,创建内存是vma管理的,我们无法直接传入,所以还是需要进一步看vma代码
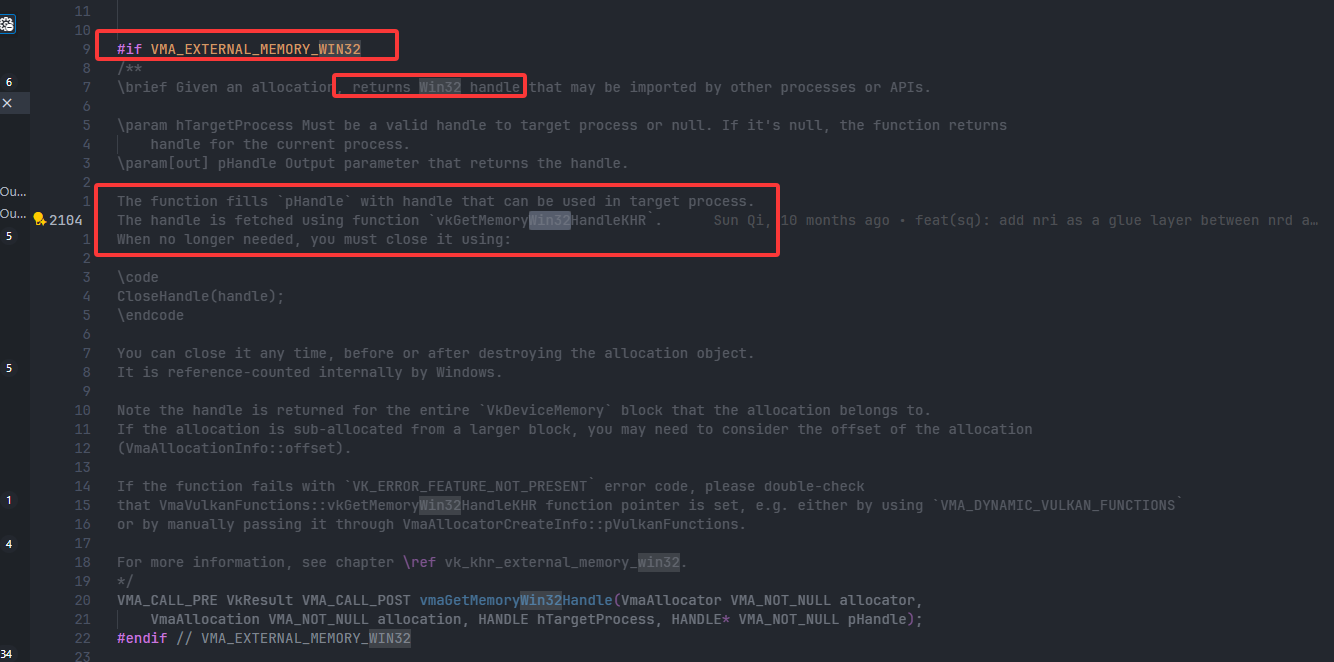
打开vma源码,搜索
win32,于是找到了:-
-
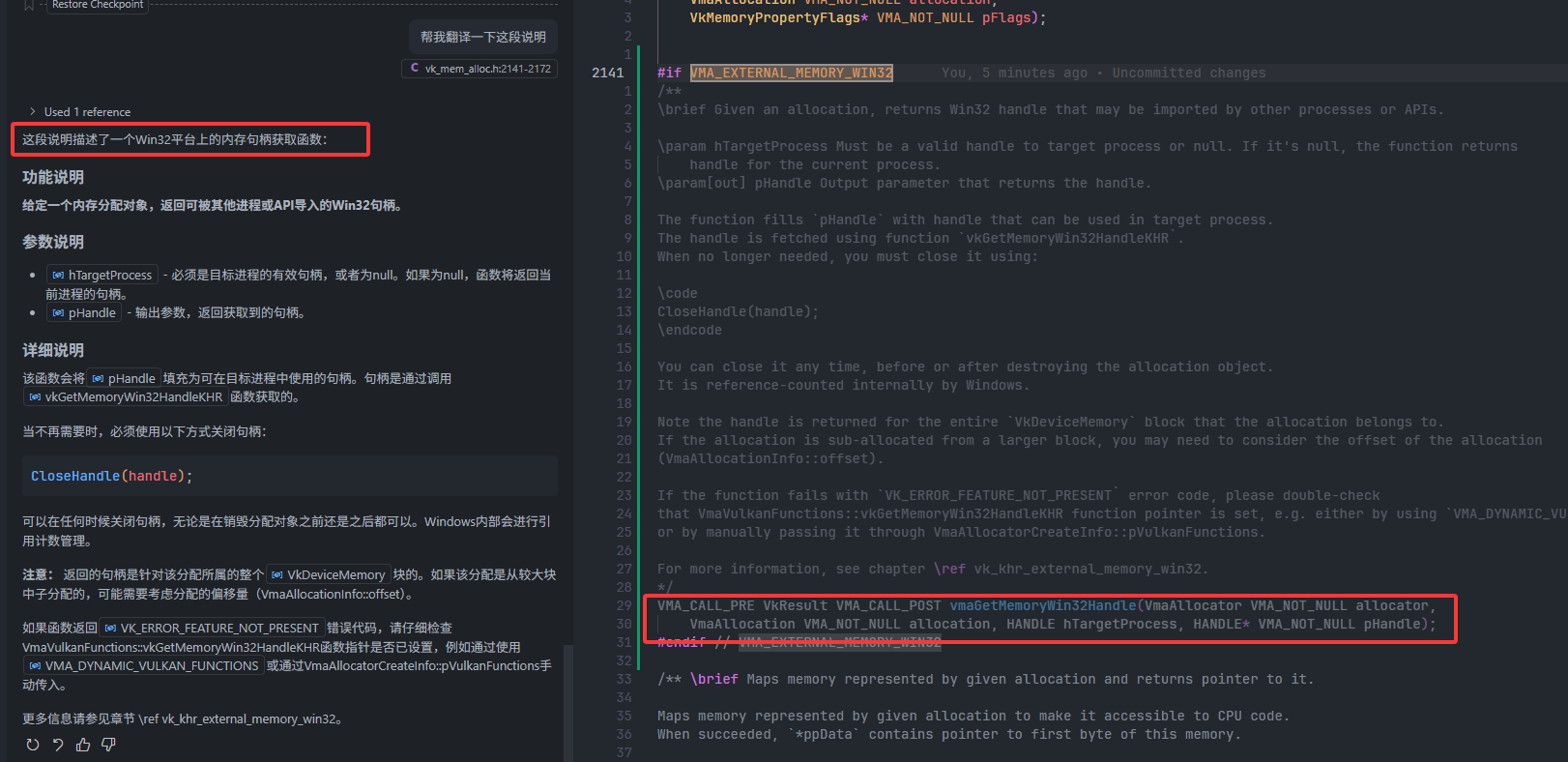
- 可以发现,vma预留了接口,需要在include的时候定义宏
VMA_EXTERNAL_MEMORY_WIN32=1,然后就可以使用函数vmaGetMemoryWin32Handle()来代替vkGetMemoryWin32HandleKHR()
-
解决方案
- 第一步,启用宏
-
- 第二步
- 替换api为
vmaGetMemoryWin32Handle()
- 替换api为
- 第一步,启用宏
子问题:
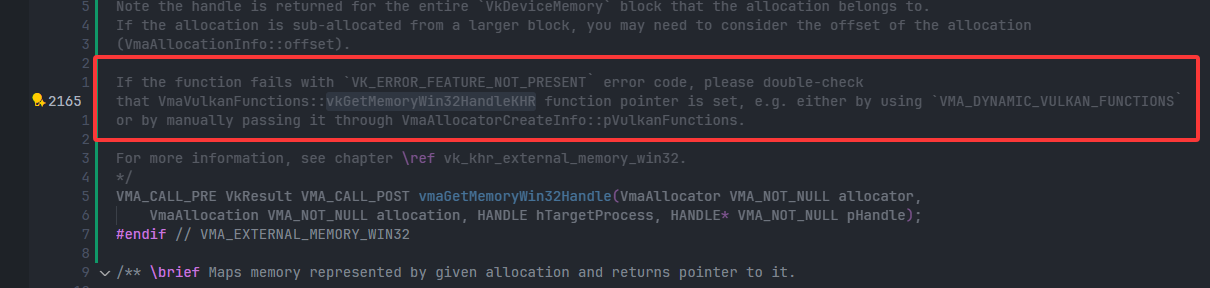
vmaGetMemoryWin32Handle()函数执行失败,返回VkResult==-8,即VK_ERROR_FEATURE_NOT_PRESENT- 子问题 原因
- 查阅vma代码
-
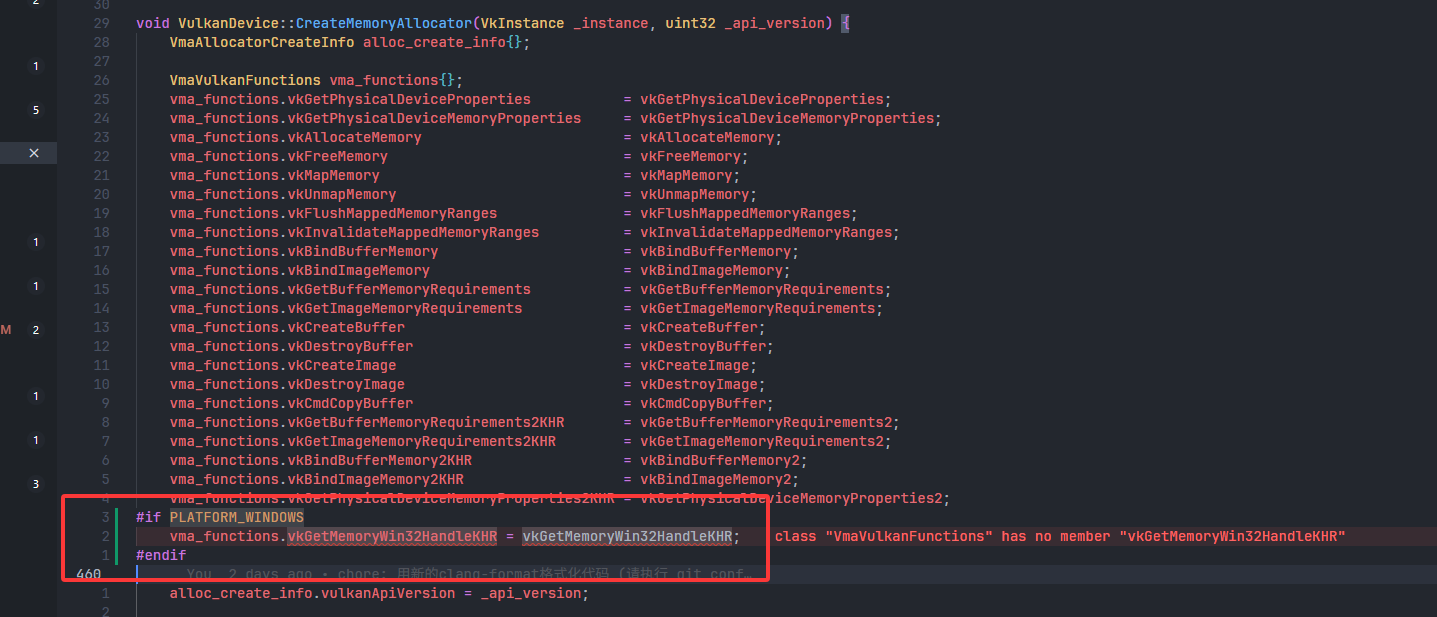
- 子问题 解决方案
- 手册中已经预计到这个情况了,这里需要新增一个函数的绑定
-
- 子问题 原因
子问题2:问题变回了 在
vmaGetMemoryWin32Handle()崩溃- 细看了一下vma源码,发现我们还需要在create info中加一个标记
关键点:在创建内存时,我们需要把对应内存区域打上
win32导出标记,才可以用api把内存进行导出- 同时,vma是一口气申请一大堆内存。为了实现的简单,我决定将MoerEngine申请的所有显存设置为
win32导出。 - 我进行了简单的实验(是否给内存添加导出标记),我发现添加导出标记并不会导致性能下降。(不严谨,仅供参考)
- 同时,vma是一口气申请一大堆内存。为了实现的简单,我决定将MoerEngine申请的所有显存设置为
问题:我们需要决定哪些Type的内存,要设置win32 handleType(导出标记)
- 解决方法:设置所有显存为win32 handleType。我们可以通过筛选
VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT来获取所有显存
- 解决方法:设置所有显存为win32 handleType。我们可以通过筛选
问题:问题没什么变化,还是出现了一长串错误信息
详细错误信息
vkBindBufferMemory(): memory (VkDeviceMemory 0x1c252400000000b5) has an external handleType of VK_EXTERNAL_MEMORY_HANDLE_TYPE_OPAQUE_WIN32_BIT which does not include at least one handle from VkBuffer (VkBuffer 0x678f7800000000fe) handleType VkExternalMemoryHandleTypeFlags(0).
The Vulkan spec states: If the value of VkExportMemoryAllocateInfo::handleTypes used to allocate memory is not 0, it must include at least one of the handles set in VkExternalMemoryBufferCreateInfo::handleTypes when buffer was created原因
- 仔细观察了一下,这是由于我将所有gpu内存设置为win32,但是在内存上创建缓冲区时,却又没有说明对应buffer/image为win32,所以发出的错误。所以,我准备把MoerEngine申请的所有Buffer和Image设置为win32导出(反正有
WITH_CUDA宏,不需要担心影响MoerEngine主分支)
- 仔细观察了一下,这是由于我将所有gpu内存设置为win32,但是在内存上创建缓冲区时,却又没有说明对应buffer/image为win32,所以发出的错误。所以,我准备把MoerEngine申请的所有Buffer和Image设置为win32导出(反正有
解决方案
VkExternalMemoryImageCreateInfo vkExternalMemImageCreateInfo = {};
vkExternalMemImageCreateInfo.sType = VK_STRUCTURE_TYPE_EXTERNAL_MEMORY_IMAGE_CREATE_INFO;
vkExternalMemImageCreateInfo.pNext = NULL;
vkExternalMemImageCreateInfo.handleTypes = VK_EXTERNAL_MEMORY_HANDLE_TYPE_OPAQUE_WIN32_BIT; // 添加此标记
image_create_info.pNext = &vkExternalMemImageCreateInfo;- 在createImage/createBuffer之前,加上这一段话,就没有
vkBindImageMemory/vkBindBufferMemory的错误了!
- 在createImage/createBuffer之前,加上这一段话,就没有
3.2.2 信号量相关
问题:在
vkGetSemaphoreWin32HandleKHR()崩溃- 问题 & 解决方案
- 需要继续给Vulkan加拓展
- 问题 & 解决方案
问题:在
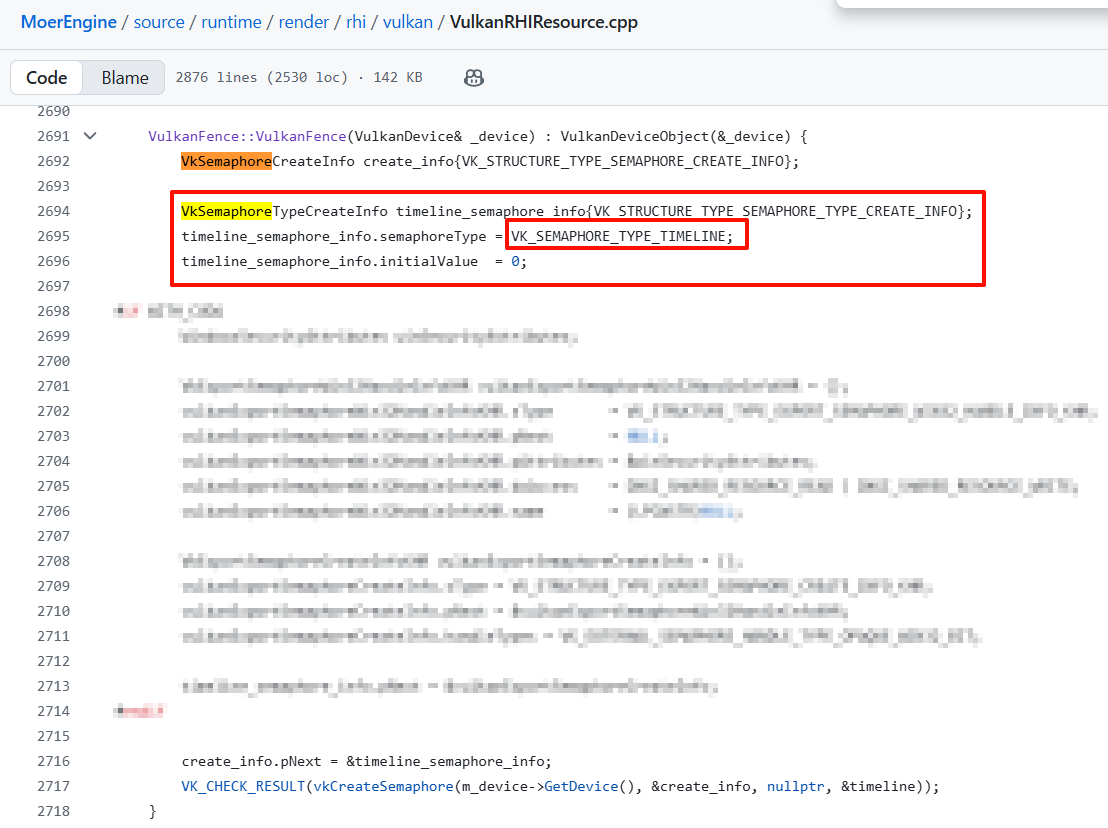
cudaImportExternalSemaphore()崩溃- 问题 & 解决方案
- Vulkan申请的信号量被定义为了Timeline类型!但是CUDA并不支持这种形式的信号量,所以我们需要修改一下定义信号量的代码
- 注:这个问题可能只在特定的Vulkan和CUDA版本下才会发生
- Before(崩溃)
-
- After(修复后)
-
- 注:两个代码中注释部分,都是关于win32导出标记的内容。但经过笔者实验,崩溃与win32导出无关,主要是因为
VkSemaphoreTypeCreateInfo与VK_SEMAPHORE_TYPE_TIMELINE
-
- 问题 & 解决方案
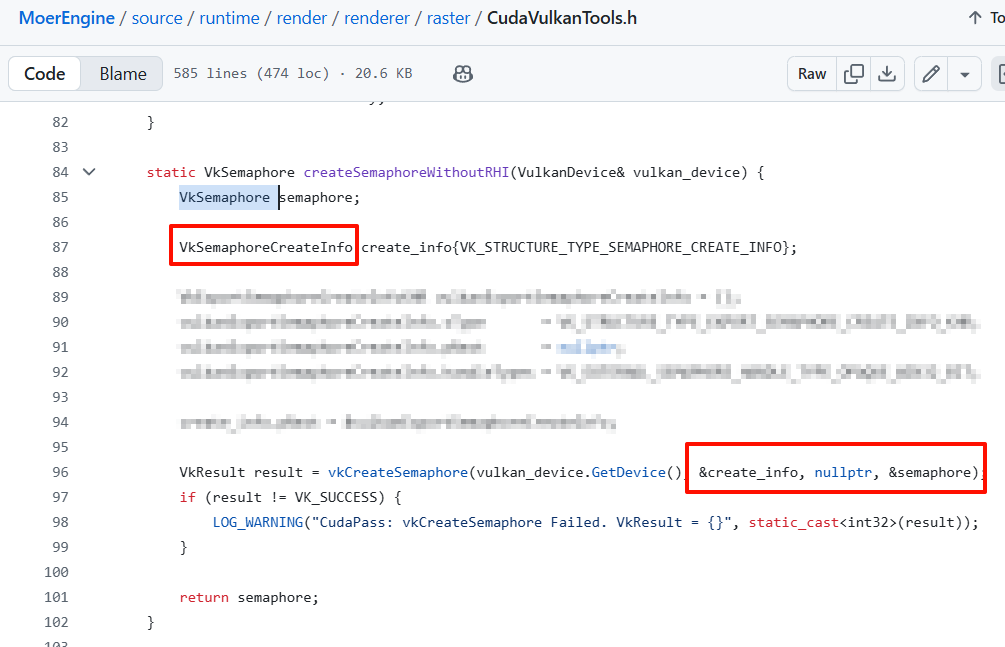
问题:无法解析的外部符号
-
- 原因 & 解决方案
.cu文件忘记include.h,导致.cu文件对应的函数实现没有被打上__declspec(dllexport)标记,从而没有被编译器导出。链接阶段就找不到对应函数了- 也请参考第三章开头的 无法解析的外部符号 解决方案汇总
-
问题:
cudaWaitExternalSemaphoresAsync(&extSemaphore, &extSemaphoreWaitParams, 1, stream_to_run)没有任何提示,就崩溃了- 原因 & 解决方案
- 忘记初始化
stream_to_run变量
- 忘记初始化
- 原因 & 解决方案
问题:输出时黑屏
- debug思路
- 换一个更简单的kernel,例如 输出固定颜色kernel。如果成功输出固定颜色,那么就是kernel代码、某个api、某个资源有问题。
- debug思路
里程碑:kernel可以输出固定颜色了!
3.2.3 CUDA读写Surface相关
问题:在cuda-samples中,采样texture代码非常奇怪,混合了两类方法
详细问题
方法一:直接访问Vulkan纹理内存
cudaExternalMemoryGetMappedMipmappedArray(&cudaMipmappedImageArray, cudaExtMemImageBuffer, &desc);
// 这里 cudaMipmappedImageArray 直接指向Vulkan纹理内存方法二:复制到单独的CUDA数组
cudaMemcpy2DArrayToArray(
cudaMipLevelArrayOrig, // 目标:独立的CUDA数组
0, 0,
cudaMipLevelArray, // 源:Vulkan共享内存
0, 0,
width * sizeof(uchar4), height,
cudaMemcpyDeviceToDevice
);
原因
- cuda-samples同时使用了两种方法,很奇怪。我个人猜测可能是为了 演示两种不同方法 或者 单纯写烂了
- 我们在MoerEngine中,使用了 方法一:直接访问Vulkan纹理内存。随后按照cuda-samples或者AI就可以完成采样代码,正确显示图像。并且后续,我发现可以直接使用CudaSurface读取图像,不需要构建Texture再从Texture上采样
3.3 TensorRT(网络相关)
TensorRT的API经常变化,使用起来十分的痛苦,AI和网络上的知识通常都是过期的。所以,请谨慎参考本节内容。笔者更推荐读者花时间阅读一遍对应版本的TensorRT文档。
MoerEngine开发时使用的TensorRT版本为10.12
TRT:TensorRT的简称
问题:图形API的Texture的形状(布局/Layout)是 (width, height, channels),而网络每个Tensor的形状(布局/Layout)通常是 (channels, width, height),怎么办?
- 解决方案
- 在我们的项目中,我们直接进行了暴力转换,没有做什么特殊处理:用CUDA写了一系列转换texture的函数,每帧将Texture的数据拷贝到另外一个Buffer中,同时进行形状转换
- 这一点貌似也没有可以优化的方法。如果想优化的话,只能在网络设计之初,就将形状修改为兼容图形API的格式,如 (width, height, channels)。如果能做到这一点,应该是可以实现0拷贝开销的
- 解决方案
问题:如何将默认为fp32的ONNX网络编译成fp16的?
- 解决方案
- 这个问题比较复杂。
总体思路有两类,可以使用新版本TRT的 强类型网络 设置方式,也可以使用旧版本TRT的设置方式。MoerEngine使用了旧版本的方式,具体请参考代码 - 根据yy指正,TensorRT设置类型的方法共有4种。这部分我确实不了解,有兴趣的读者可以自行查看(逃)
- 这个问题比较复杂。
- 解决方案
问题:绑定和缩放Buffer时,调用
d_surface_xxx[0]时,为什么直接崩溃了?- 原因
d_yyy是一个显存上的数组,在CPU上是无法访问的。所以直接在C++端(CPU)访问显存上的数组,就会直接崩溃,并且没有任何提示。
- 解决方案
- 将数组地址和索引传入CUDA kernel,在GPU上访问
- 原因
3.3.1 解析每种Texture的布局
问题:
cudaMalloc申请的显存被使用时,显示an illegal memory access was encountered。另一个根源类似的问题:提示misalign address-
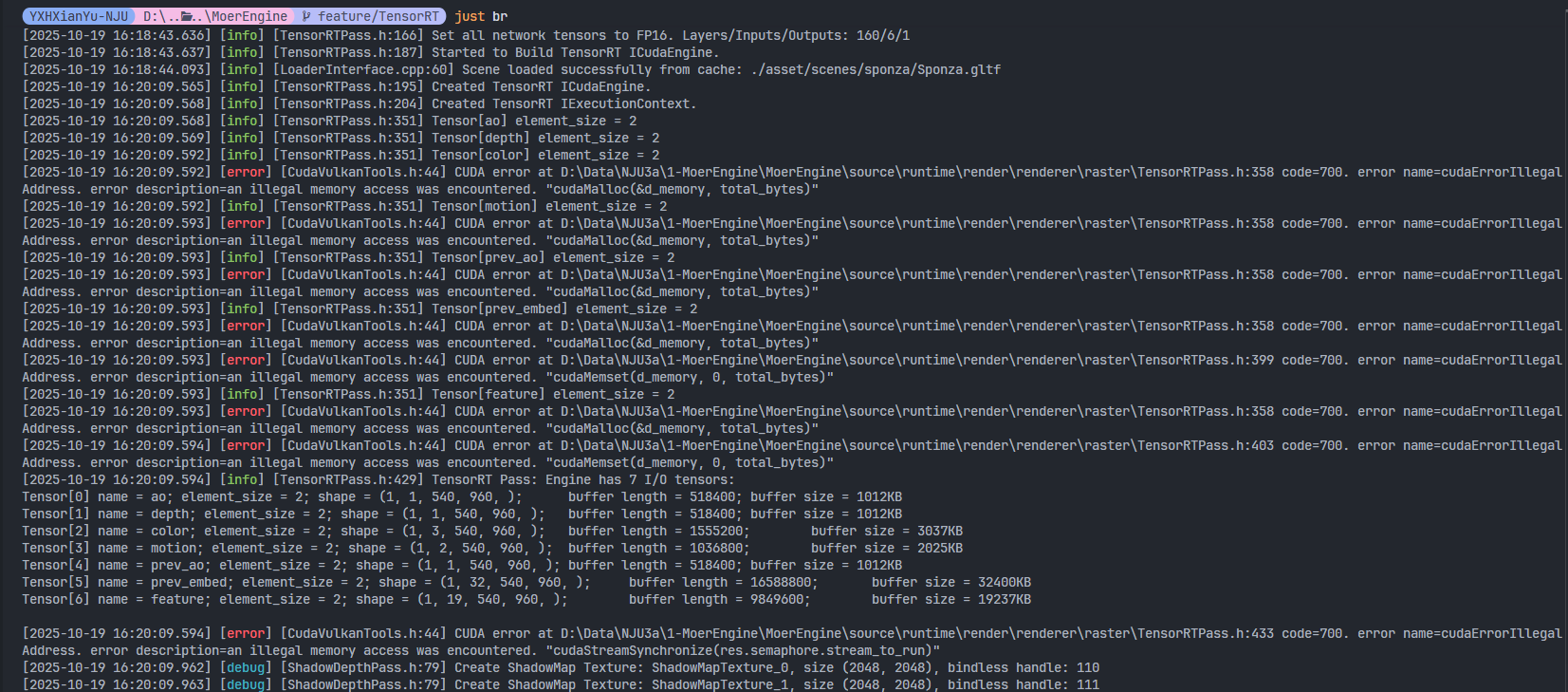
- 线索
- 如果BindEmptyBuffers,或者BindBuffers把CUDA kernel去掉(不执行格式转换),则可以正常运行
- 原因
- 不同Texture的格式不一样,我在CUDA kernel中都当作 r8g8b8a8 处理,导致数组越界
- 换句话说,这个问题,本质上是访问了非法显存,导致后续所有显存访问全炸了
- 解决方案
- 这个问题比较麻烦,分为多步:
- 设置CUDA解析Texture的格式
- 设置正确的采样方式、步长
- 这个问题比较麻烦,分为多步:
-
第一步:设置解析格式
- 我们需要手动地分析并处理每种需要使用的Texture类型。例如:
- DepthTexture (PF_D32_SFLOAT)
- ColorTexture (PF_R8G8B8A8_UNORM)
- MotionVector (PF_R32G32_SFLOAT)
- etc.
- 具体可以参考MoerEngine中,
CudaVulkanTools.h: static FormatDescriptor getCudaFormatDescriptor(const EPixelFormat& pf)函数
switch (pf) {
case PF_R8G8B8A8_UNORM: { // color
result.desc.x = 8;
result.desc.y = 8;
result.desc.z = 8;
result.desc.w = 8;
result.desc.f = cudaChannelFormatKindUnsigned;
result.read_mode = cudaReadModeNormalizedFloat; // 只影响texture:归一化读取
result.element_type = EFormatElementType::UCHAR;
result.element_type_count = 4;
break;
}
case PF_D32_SFLOAT_S8_UINT: {
assert(false);
// cuda不支持这种格式!
break;
}
// .....处理每种不同texture
}- 我们需要手动地分析并处理每种需要使用的Texture类型。例如:
第二步:CUDA kernel采样时,适应不同步长和类型
- 具体看MoerEngine代码吧,实际操作的时候挺麻烦的
-
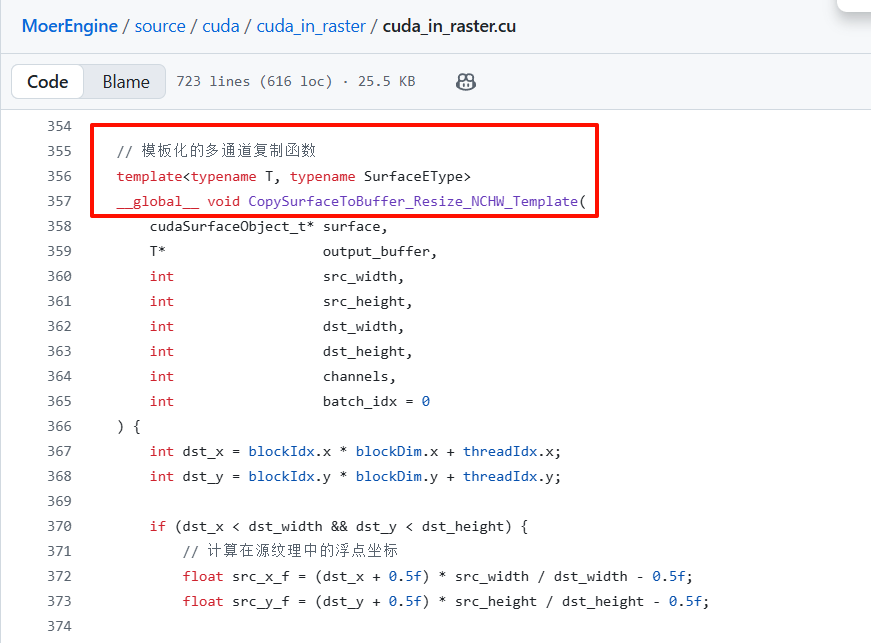
大坑:CUDA不支持
VK_FORMAT_D32_SFLOAT_S8_UINT- 原因
- 总所周知,在大部分图形API中,深度测试和模板测试的RenderTarget都默认合并在一个Texture中。MoerEngine也遵循这个方式,将DepthTexture设置为
PF_D32_SFLOAT_S8_UINT,前32bit用于深度测试,后8bit用于模板测试,然后有24bit的无效位- 注:
PF_D32_SFLOAT_S8_UINT占用64bit
- 注:
- 但是,CUDA不支持32bit+8bit的划分方式!CUDA只支持每个RGBA都占用相同bit数,例如32+32或者8+8
- 总所周知,在大部分图形API中,深度测试和模板测试的RenderTarget都默认合并在一个Texture中。MoerEngine也遵循这个方式,将DepthTexture设置为
- 解决方案
- MoerEngine在启用CUDA特性后,会不执行模板测试,并且将DepthTexture的格式改为
PF_D32_SFLOAT
- MoerEngine在启用CUDA特性后,会不执行模板测试,并且将DepthTexture的格式改为
- 原因
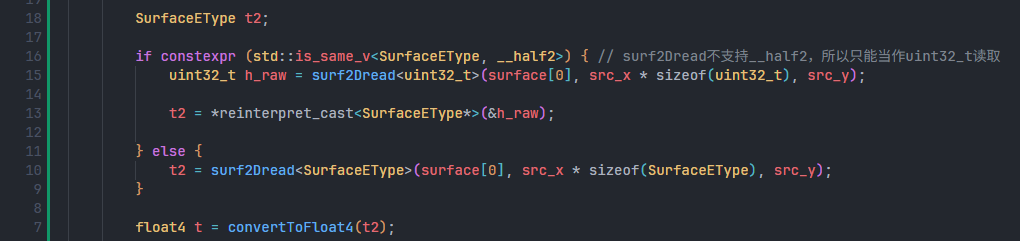
问题:CUDA kernel中读取MotionVector后,提示
an illegal memory access was encountered- 原因
surf2Dread()不支持__half2类型,即 不支持 一个长度为2的float16Vector
- 解决方案
- 使用
uint32_t读取,然后reinterpret_cast成__half* -
- 使用
- 原因
总结:计算机在解析一个Texture时,需要考虑如下几个方面
- (单个元素)bit数量:8、16、24、32、64
- (单个元素)数据类型:unsigned、signed、float
- (单个元素)通道:r、rg、rgb、rgba、bgr etc
- (整体)布局:(width, height, channels)、(channels, height, width)
- 我们在实现第一步和第二步时,都需要考虑这上面四个步骤。例如:
- MotionVectorTexture为
R32B32_SFLOAT。那么,我们就需要设置步长为64bit,每32个bit看作一个元素,这个元素按照float来解析 - ColorTexture为
R8G8B8A8_UNORM。那么,我们就需要设置步长为32bit,每8个bit看作一个元素,这个元素按照unsigned int来解析。并且解析后,需要将0255映射为01(因为是UNORM)
- MotionVectorTexture为
问题:提示
ptxas fatal : Unresolved extern function '_ZN4Moer4Cuda15convertToFloat4I7__half2EE6float4RKT_'- 原因 & 解决方案
- ptxas 是CUDA的汇编和链接器,这里就是链接不上的问题
- 我忘记给
__half2特化一个convertToFloat4()模板了,补全即可
- 原因 & 解决方案
开香槟🍾🍾🍾
- 到这里,实际上你就可以在你的渲染器中运行CUDA kernel和PyTorch中的网络了!
- 可喜可贺,可喜可贺。笔者当时开心了好几天,挺不容易的
- TensorRT这块,实际上还有好大一部分关于Plugin的内容。但由于最后实验效果不佳,并且我懒了,所以就不继续整理了。有需要的话可以给我发邮件
打包
为了简化,这里只考虑Debug模式的打包。Release同理,只不过可能会多一些代码相关的问题。
问题:对于MoerEngine来说,打包的流程是什么?
- MoerEngine在构建的时候,已经收集了继续所有的依赖项的动态库
.dll。只有LibTorch和TensorRT的动态库.dll我们是通过PATH环境变量来引入的。所以,我们只需要简单的将./target/bin/Debug/目录下的所有文件进行打包即可。 - 用户在使用的时候,需要手动安装CUDAToolkit、LibTorch、TensorRT,并且将LibTorch和TensorRT的lib目录添加进PATH
- MoerEngine在构建的时候,已经收集了继续所有的依赖项的动态库
问题:在Enable CUDA Pass之后,引擎崩溃。同时,3080和3060崩溃,但是5080正常运行
原因
- nvcc中有两个关键编译选项
arch=compute_XY和code=sm_XY/compute_XY arch=compute_XY,表示你的CUDA代码编译时候的计算能力,这里类似于Vulkan API版本和拓展。计算能力越高,拓展和优化就越多code=sm_XY或code=compute_XYsm_XY,nvcc编译器会直接生成针对特定SM (Streaming Multiprocessor)架构的 SASS(二进制机器码)compute_XY,nvcc编译器会生成针对特定ComputeCapability的 PTX(ParallelThreadExecution 并行线程执行)
- 所以,MoerEngine这里的问题,应该就是默认生成对应机器的SASS码,导致其他ComputeCapability的显卡就无法运行
- nvcc中有两个关键编译选项
解决方案
在CMake中添加
set_target_properties(moer_cuda PROPERTIES
CUDA_ARCHITECTURES 86
)这样,nvcc编译命令中就会出现以下内容,从而编译出compute_86的PTX,支持低版本的显卡
-gencode arch=compute_120,code=sm_120--generate-code=arch=compute_86,code=[compute_86,sm_86]
也可以这么做
set_target_properties(moer_cuda PROPERTIES
CUDA_ARCHITECTURES "61;75;86;90;120"
)- 但需要注意,经实验,61和75还是不支持,至少需要86
问题:LibTorch依赖库,是否需要debug版本?
- 回答
- 都行,debug或者release都行
- 回答
问题:启动后,弹出终端后,无任何日志输出,崩溃,系统提示
TODO- 回答
- 需要CUDA12.8及其他对应版本
- 换句话说,打包的话,CUDA Toolkit必须是编译时的对应版本
- 解决方案
- 换CUDA12.8
- 回答
问题:启动后,弹出中断后,日志提示了Starting(进入了main函数),然后崩溃,无任何提示
- 回答
- 显卡是Quadro 4000 即 SM7.5
- 最小版本应该还是SM8.6
- 解决方案
- 换机器,显卡至少需要SM8.6
- 回答
问题:在MoerEngine中,启动网络后,输出内容没有任何变化
- 原因
- 在不同分辨率下,操作系统会自动对窗口进行缩放,导致触发了引擎Textures的重构建;但是MoerEngine网络部分的Texture重构建代码还没写,导致自动缩放后,纹理的索引就失效了(即CUDA部分的纹理和缓存索引都指向失效显存)
- MoerEngine日志会提示“Size Changed”
- 临时解决方案
- 点击OpenScene,重新载入场景,这样就会用新分辨率重新构建所有纹理
- 在配置文件中,把默认分辨率直接修改为操作系统自动缩放后的分辨率
- 解决方案
- 实现一下CUDA纹理重创建
- 原因
4. MoerEngine部署
请在 commit a7ce9b2或 v0.0.1版本上进行CUDA相关的测试,其他版本不保证CUDA相关功能稳定。
另外,MoerEngine目前非常初步,如果你遇到了任何问题,欢迎提出Issue。因为这可能是我们的问题,而不是你操作的问题(逃)。
自v0.0.1版本之后,引擎支持了HDR纹理。但用于测试的网络对HDR支持不足,所以网络在HDR下,存在许多artifact。(v0.0.1版本为LDR纹理;commit a7ce9b2 为HDR纹理,使用Reinhard ToneMapping映射为LDR)
5. 总结 & MoerEngine
这一系列的功能,笔者陆陆续续实现了一个多月,比预期多花了不少时间。实现的过程中,最大的收获是刷了Vulkan、CMake、深度学习库的熟练度吧。总的来说,还挺有意思的。
一个遗留的问题,就是没有成功集成 带有Plugin的ONNX网络。因此,如果PyTorch网络用到了tiny-cuda-nn或者使用了一些自定义算子。那么,MoerEngine现阶段也没有办法集成这些网络。
此外,安利一下我们组的实时渲染引擎 MoerEngine。笔者硕士在读期间会和组里的其他同学一起持续的维护和改进这个引擎,所以笔者可以保证在未来的1~2年中,这个渲染引擎都会持续地升级和改进,并且尽量处理所有的issues和PR。
对于社区来说,开源渲染器太常见了。并且,MoerEngine的代码不算优雅,参考和深入学习的价值也比较低,那么对于社区而言,它有什么存在的意义吗?那说实话,它对社区的意义确实不大。至于MoerEngine对于笔者的意义,就是让我可以名正言顺地在硕士就读期间,天天写引擎造轮子,这是一种享受。
但我确实想更进一步,让它对社区有意义。鉴于从实际应用层面,MoerEngine是很难超过商业引擎的,但它的优势是有着实验室的长期劳动力,换句话说,它的维护成本很低,不需要产生商业价值就可以活下去。
如果有时间的话,我接下来会从两方面进行尝试。
第一个方面,我会尝试性地写一些基于MoerEngine的渲染算法教程或者指引。从最简单的后处理算法(ToneMapping, Bloom, SSAO, RTAO, SSR, TAA),到一些更复杂的算法,从而让用户能学习到对应的 引擎无关 知识。在实现了算法之后,用户也可以方便的和同类算法进行比较,鼠标点击一下就可以对比不同算法的效果,从而了解自己是否有遗漏的算法细节,确保代码尽可能正确。
第二个方面,MoerEngine会持续地接收PR,并且开放重复造轮子的可能。例如,虽然MoerEngine已经有了SSR算法,但你也可以添加一个更好的SSR算法,引擎内可以同时兼容多种算法。此外,MoerEngine也会提供一些从零实现一套渲染器的接口。例如,你可以直接绕过整套RHI,直接使用Vulkan API来将渲染场景,从零实现一个自己的渲染器(不需要再搭建一遍其他基础设施)。
总之,这大概是一个饼,一个以学习知识为核心的渲染器的饼,属于有生之年系列。也可能会咕,随缘。
最后,如果你觉得这篇文章对你有帮助 或者 你也对MoerEngine有兴趣,那么欢迎给 MoerEngine 点一个star。